As multimodal large language models (MLLMs) advance, Generalist Virtual Agents (GVAs) face challenges like reliance on outcome-based rewards and labor-intensive manual annotations, lacking fine-grained process supervision and inference-time scalability.
We propose ![]() Similar, a step-wise, multi-dimensional reward model defining five evaluation dimensions (Helpfulness, Odds of Success, Efficiency, Task Relevance, Coherence), paired with an MCTS-P algorithm to automatically collect cross-platform annotated data.
Similar, a step-wise, multi-dimensional reward model defining five evaluation dimensions (Helpfulness, Odds of Success, Efficiency, Task Relevance, Coherence), paired with an MCTS-P algorithm to automatically collect cross-platform annotated data.
Introducing ![]() SRM, the first benchmark for step-wise, multi-dimensional reward model evaluation, comprising 78k-training (
SRM, the first benchmark for step-wise, multi-dimensional reward model evaluation, comprising 78k-training (![]() SRMTrain) and 32k-test (
SRMTrain) and 32k-test (![]() SRMEval) datasets across Web, Android, Linux, and Windows.
SRMEval) datasets across Web, Android, Linux, and Windows.
Experiments show Similar achieves 61.2% avg. accuracy on ![]() SRMEval, outperforming baselines by 13.2%, and boosts task success rates by up to 35.9% during inference, demonstrating its effectiveness in guiding GVA training and scaling.
SRMEval, outperforming baselines by 13.2%, and boosts task success rates by up to 35.9% during inference, demonstrating its effectiveness in guiding GVA training and scaling.
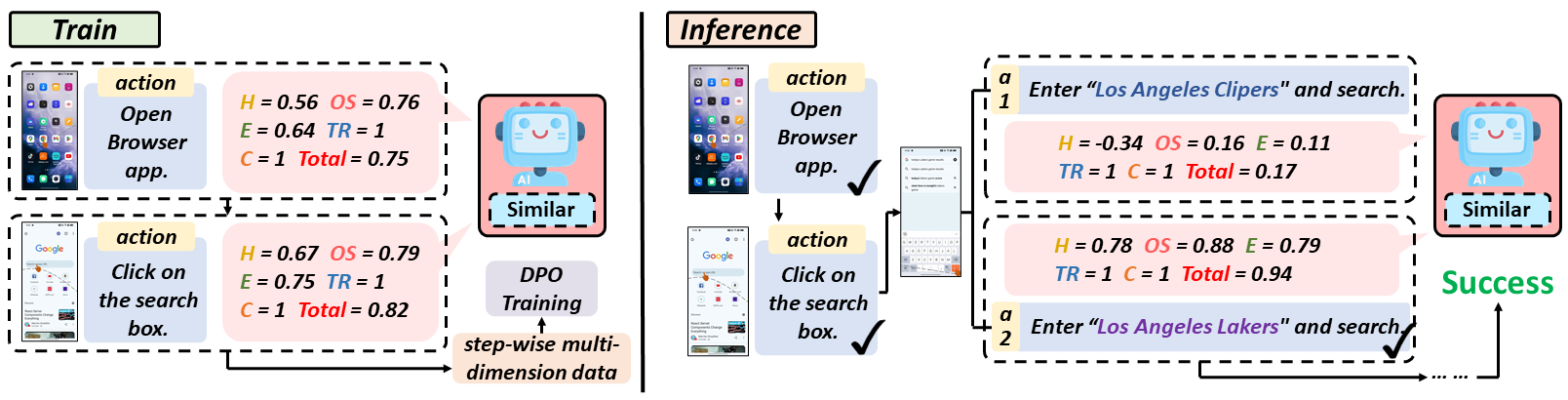
GVAs are designed to process multimodal inputs (e.g., UI elements, text, visuals) and navigate digital environments to perform tasks. However, traditional training methods rely heavily on outcome-based rewards, which lack the granularity needed to guide agents effectively through complex tasks. To overcome these challenges, we propose ![]() Similar, a reward model that provides multi-dimensional, step-wise supervision signals to guide agent learning and reasoning.
Similar, a reward model that provides multi-dimensional, step-wise supervision signals to guide agent learning and reasoning.
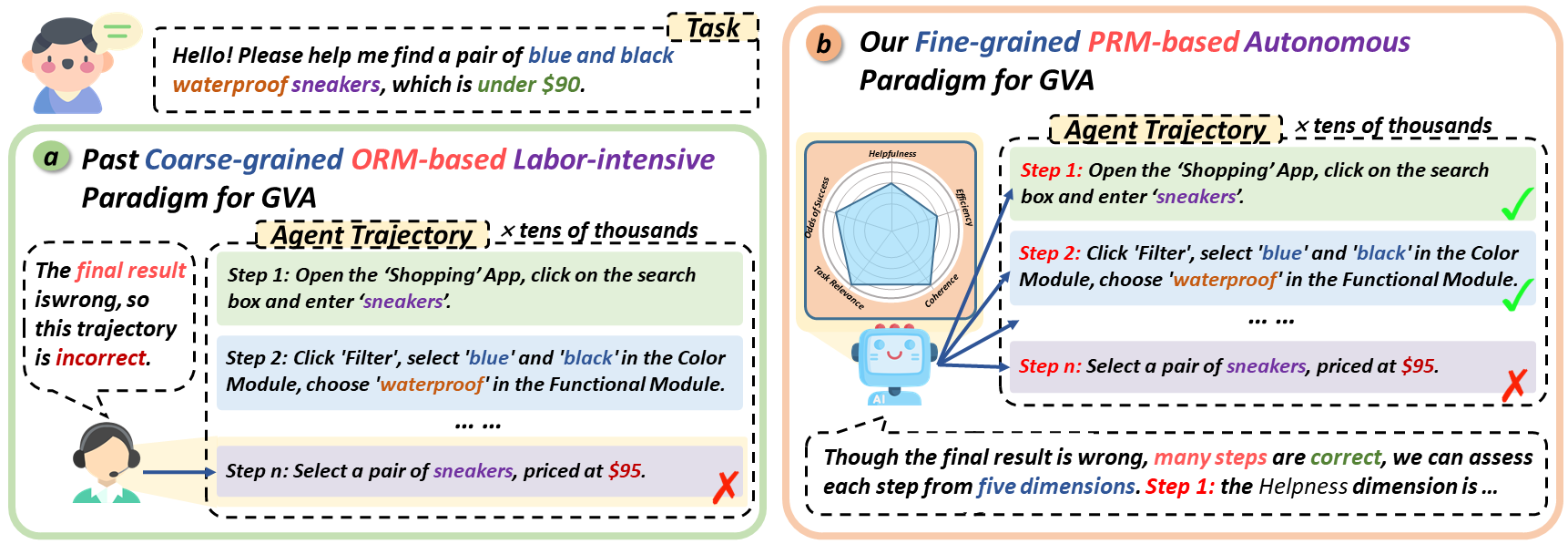
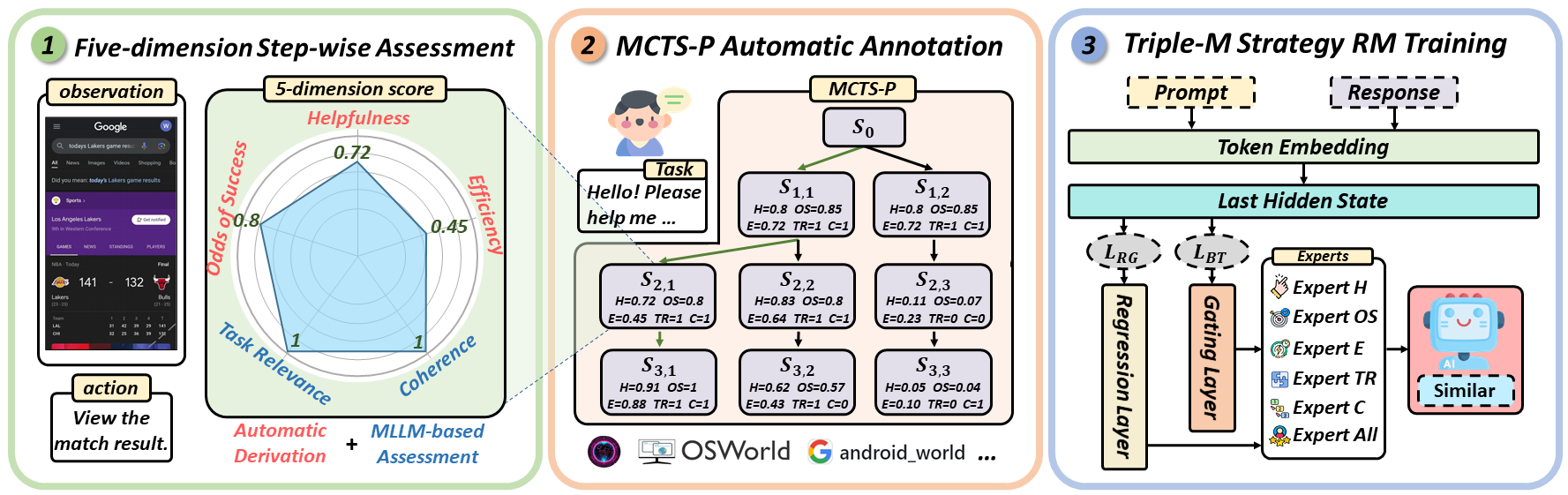
(1) Five Key Dimensions: We define five dimensions for step-wise GVA assessment and introduce an automated framework using MCTS-P to collect fine-grained, cross-platform reward model data annotations.
(2) Triple-M Strategy: We propose a Triple-M strategy to train ![]() Similar, integrating multiple dimensions and generating synergistic gains for robust, fine-grained feedback.
Similar, integrating multiple dimensions and generating synergistic gains for robust, fine-grained feedback.
(3) SRM Benchmark: We introduce ![]() SRMEval, a multi-step, multi-dimensional benchmark for evaluating reward models, advancing research in reward model performance assessment.
SRMEval, a multi-step, multi-dimensional benchmark for evaluating reward models, advancing research in reward model performance assessment.
(4) Superior Performance: Our approach achieves superior GVA performance across diverse tasks and environments, demonstrating the effectiveness of step-wise multi-dimensional assessment and synergistic expert integration.
Since reward models are crucial for enhancing GVAs' performance, and prior research has not focused on evaluating specific reward models, we propose ![]() SRMEval, the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation.
SRMEval, the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation.
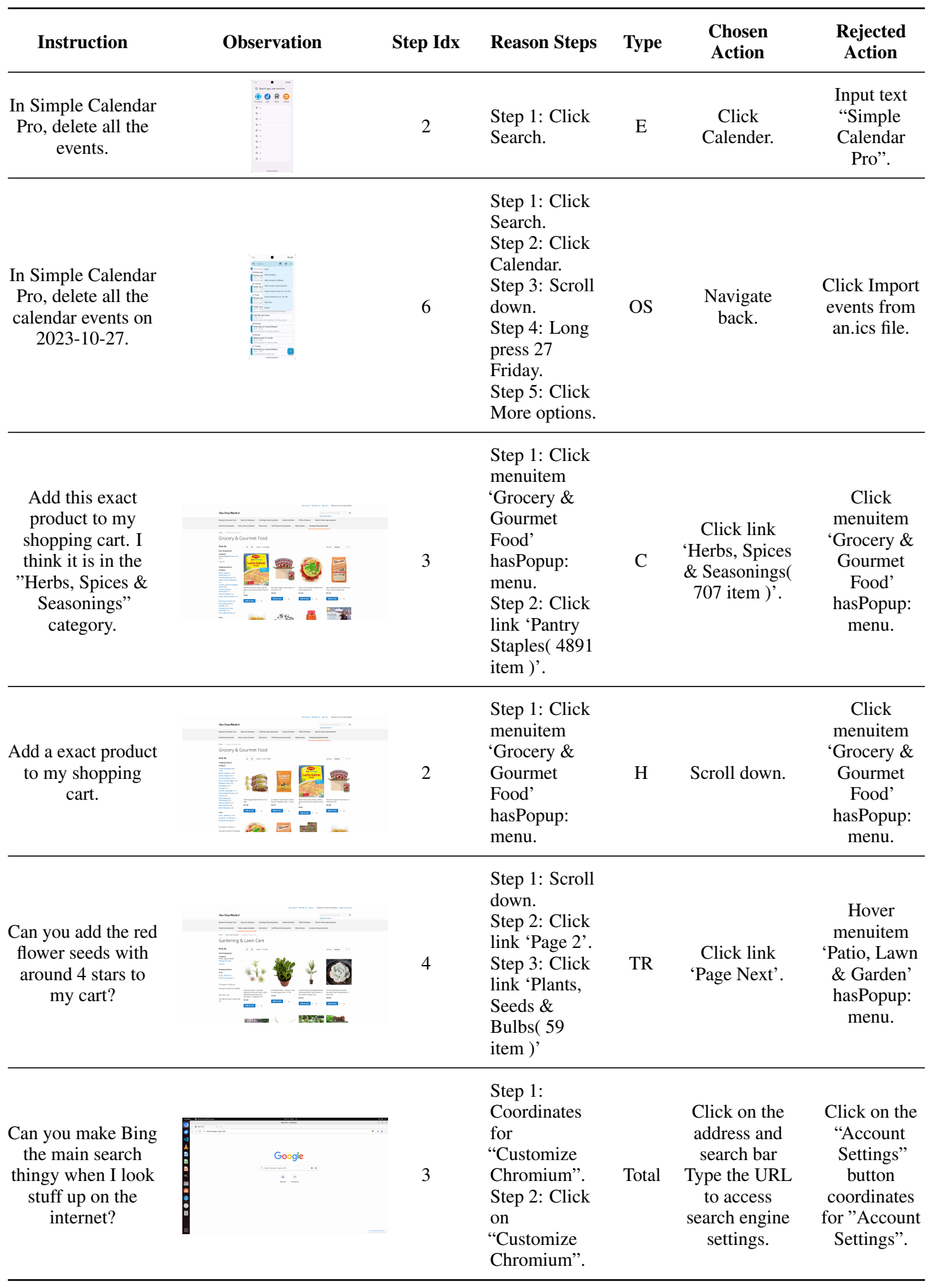
We proposed a new task for reward models in the virtual agent domain: Selecting the better action (i.e., the chosen action) from two actions at step i for a specific evaluation dimension. The evaluation metric is Accuracy, measuring the reward model's ability to select the better action. Accuracy is calculated under a specific evaluation type.
@misc{miao2025boostingvirtualagentlearning,
title={Boosting Virtual Agent Learning and Reasoning: A Step-wise, Multi-dimensional, and Generalist Reward Model with Benchmark},
author={Bingchen Miao and Yang Wu and Minghe Gao and Qifan Yu and Wendong Bu and Wenqiao Zhang and Yunfei Li and Siliang Tang and Tat-Seng Chua and Juncheng Li},
year={2025},
eprint={2503.18665},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.18665},
}